Rest In Peace, TotalBiscuit.
Rest In Peace,
John Peter “TotalBiscuit” Bain
July 8, 1984 - May 24, 2018

lol hi
Rest In Peace,
John Peter “TotalBiscuit” Bain
July 8, 1984 - May 24, 2018
In my last post, I briefly discussed the impending closure of Funorb on the 7th of August this year, and that I started recording all my Arcanists gameplay in order to keep an archive of my final moments of fun with the game.
This highlights a problem in gaming where online games die without official support for playing them past server shutdown. We want to play the game, we bought copies of the game, and the code for the servers to make the game run exists, yet because someone decided it to no longer be a benefit to run them, that’s it. The game’s gone.
This can be particularly frustrating for the fans, and it certainly sucked when I heard that about Jagex’s Funorb, which hosts my childhood favourites Arcanists and Steel Sentinels, along with other great games like Armies of Gielinor and Void Hunters.
Even with the limitations my parents put on my gaming habits back during highschool and the fact that I only had a Funorb subscription for a few short months (since we didn’t have a credit card and I was paying through a friend), I racked up 1080 ranked games with Arcanists and 309 ranked games with Steel Sentinels, equating to 347 hours of ranked gameplay (assuming 15 minutes per game), and many more unranked games (particularly with Steel Sentinels). I absolutely loved Arcanists and Steel Sentinels back then, and I still believe they’re amazing and fun games that I’d love to return back to on occasion, even if it’s just to play with friends and have some casual fun.
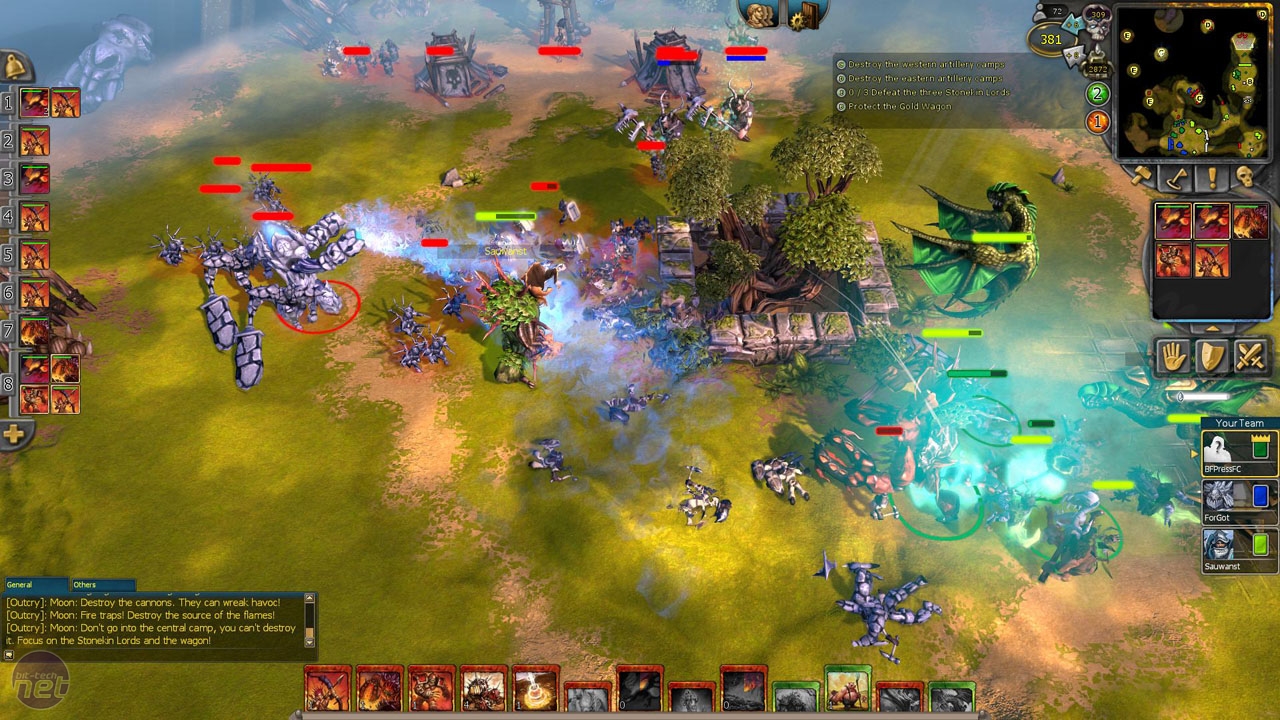
Similarly, I was a huge fan of EA’s Battleforge back in the day for its unique and riotous-fun take on the real-time strategy formula, awesome theme, and its lovely and colourful art direction.
Battleforge shut down on the 31st of October, 2013, which was also the day of my highschool HSC Physics exam. Despite the importance of that exam, I still decided to make the most of Battleforge’s final hours, even sleeping at my computer desk with Battleforge open the night before the exam.
Thankfully, it’s not always doom and gloom. If a game is popular enough, people are smart enough to eventually figure something out.
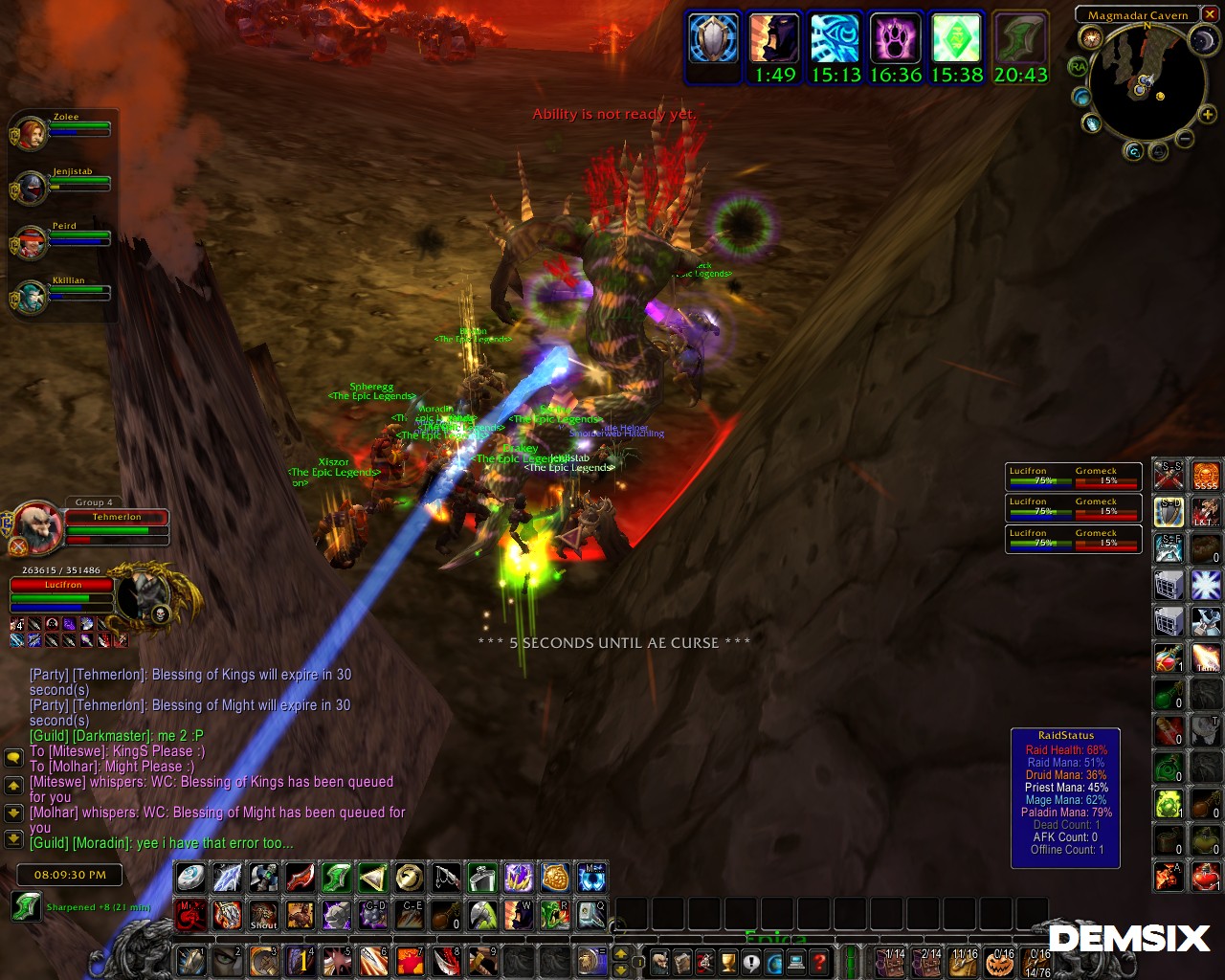
Player-made private servers are a staple for MMORPGs such as World of Warcraft, Runescape, older titles such as Ultima Online, and dead titles such as Star Wars Galaxies.

Even for currently-supported MMORPGs such as World of Warcraft, private servers are still popular for allowing players to play older versions of these titles, particularly if these older versions are preferred over newer versions, or simply for the nostalgia. Private servers also naturally gave full control to the community, and even allowed adding of custom content to the games.
Moving away from MMORPGs, many other online games have also been successfully revived by players.
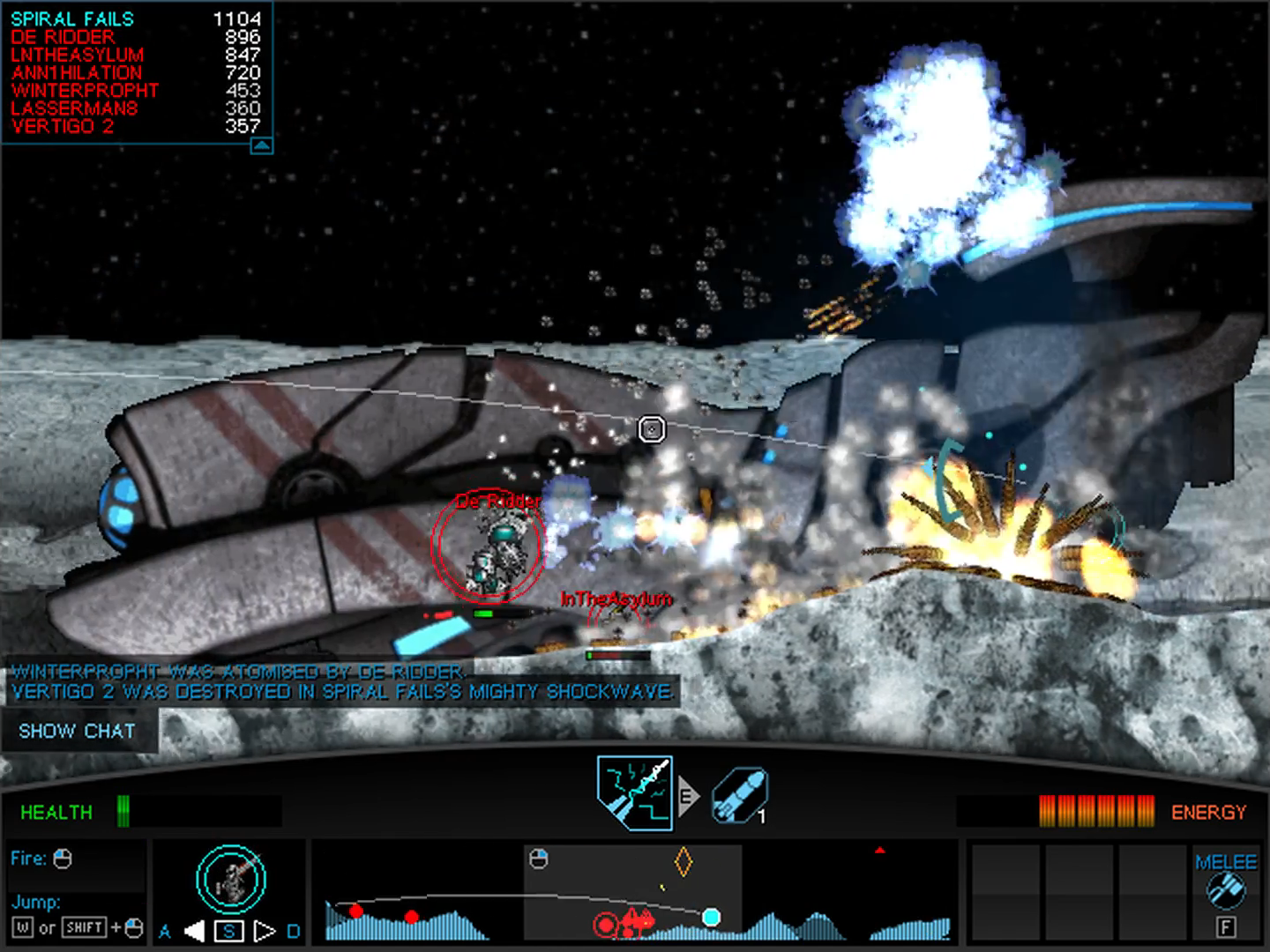
Official servers were axed in 2011 for Supreme Commander: Forged Alliance, though LAN play and a campaign were still available. The Forged Alliance Forever project was the community’s response to this, giving the game a multiplayer lobby and match-making (thus avoiding the need for VPNs) that continues to run to this day, and a community client with frequent patching for bug fixes and balance changes.
The Forged Alliance Forever client even goes well-beyond the game’s original functionality, adding additional features such as improved map and mod management, online map/mod/replay repositories, social features, a rating system, and co-op campaigns.

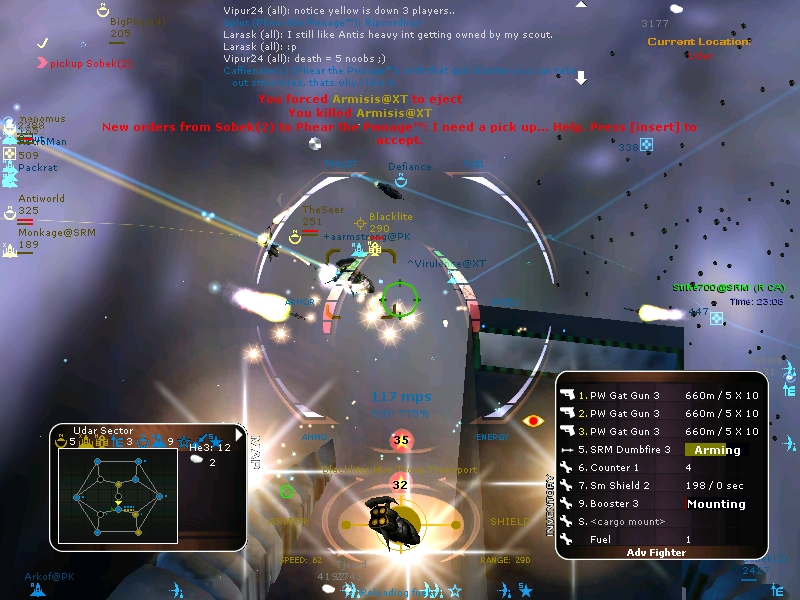
Allegiance is a shining example of what happens when a company supports its community’s efforts for revival. Allegiance’s online servers got the axe back in 2002, but succeeded well beyond its expiration date thanks to its small but loyal following.
LAN play was originally supported, which allowed the community to continue playing in a limited fashion. In 2004, Microsoft released the source code under a shared software license, smoothly allowing continued development by the community under the name FreeAllegiance and allowing the hosting of a community-driven online lobby. And just last year, Microsoft converted the software license to the open-source MIT license, allowing the game to be re-released onto Steam.
I discovered the game around 2005 through a free games magazine and despite being absolute terrible at it, I played the game for years until my family upgraded all the computers to Windows Vista. I stopped playing due to lack of support for Vista, though it improved eventually, allowing me to occasionally dive back in.
Despite the dated graphics and technology, Allegiance in my opinion stands the test of time for its uniqueness, community, and gameplay breadth and depth that few games are able to compare with.
On the other side of the spectrum, companies are also known to flex their legal rights against server emulators, with Asheron’s Call and it sequel Asheron’s Call 2 being merely two examples of emulator efforts falling to legal cease and desist orders.
Turning our sights back to Funorb and Battleforge, perhaps there’s still hope.
Hanging around the Funorb unofficial Discord, there are certainly talks of reverse-engineering the games and building server emulators, and people who seem to have looked through the code and the internal game logic. While I haven’t seen anything concrete yet, I’m quite hopeful that someone’s going to make a server emulator at some point. I might even take the challenge up myself if need be (it can be a great learning experience!).
Also, at the time of writing, a Battleforge server emulator seems a lot closer to being “ready”, with this recent announcement by the Skylords Reborn project on progress towards an open beta, and videos of the game working such as this video with early-alpha footage:
Really, it’s all just a matter of time.
There will always be a time when a games company no longer sees the continued support of an old game viable. The reason for this I think is fairly obvious: games companies are businesses, and legal complications may even prevent them from acting for the interests of the players.
Even if a company wanted to release server software, they’d need to spend time sanitizing it to remove anything unfit for distribution, and this could even prove impossible depending on the design of their systems. And even with the technical challenges sorted, unless a games company is doing it for PR, there’s no good reason for them to spend employee hours to solve both the technical and legal challenges that may exist.
There’s also the problem of avoiding cannibalizing its newer products, further disincentivizing any good will. As an example, consider a scenario where a company wants to release a new online-only arena shooter while also killing off support for an older online-only arena shooter. If the company released server programs for the old title, they’d consider it more likely that some people (no matter how small) who would’ve bought the newer title would instead continue playing the older title. It may not even matter how small the possibility is for the release of server programs to cannibalize. Releasing server code can potentially pull customers from any present and future titles.
Keeping assets as close as possible is also advantageous, giving a company more exclusive rights and control over the market. Relinquishing a great deal of control over a product and allowing public hosting means they lose the option of reusing it at a later date, perhaps to revive and subsequently monetize it, or to sell the assets off to another developer.
I’m sure there are plenty more points of discussion, especially since I haven’t even attempted to touch any legal problems that may arise (such as re-licensing). But the point still stands: companies gain nothing from giving communities control and can even suffer for it, so why should they bother?
Letting go of a well-loved videogame can be particularly painful. Oftentimes, we’ve invested so much of our lives on the particular game, spent so much time playing it, thinking of how we could get better at it, formed communities and friendships, and made plenty of fond memories. Even if you hardly play a particular game nowadays, losing the ability to play it can feel like losing a part of your life.
For games with no dependence on online services (such as retro console games and most single-player PC games), it’s not too bad to simply lose the disk, cartridge, and/or console. Someone probably ripped it and the game is probably playable on a console emulator. Or in the worst case, you’d likely still be able to find a second-hand copy of the game for sale somewhere, and an old console or a copy of Windows 95 to play it with. Everything is self-sufficient enough that it’s quite easy to go back to.

But for online games with complete dependence on online services, the loss of these services renders them completely unplayable on their own. The online server components are often highly complex yet kept secret by the company that hosted them, meaning a major technical effort is required by a group of skilled reverse-engineers in order to bring it back. Depending on the game, this can take years before an acceptable server emulator is developed (if at all). It’s been almost 5 years yet the Skylords Reborn project is only just moving towards an open-beta for its Battleforge server emulator. And even if the game gets a server emulator, its accuracy depends on how well people understand the game from the outside. (Exact precise accuracy may not matter, but it’s still worth noting.)
If the game is niche, unique, and actually good, its loss can be even more painful. If similar-enough games exist, then the loss of an original isn’t so bad. They won’t be the same, but they can be similar enough to still enjoy the same gameplay. However, this is certainly not the case for Arcanists, Steel Sentinels, Battleforge, and Allegiance. All of these are great games that offer unique gameplay elements and combinations unseen elsewhere.
The uniqueness factor perhaps applies a bit less to Supreme Commander’s fairly bread-and-butter RTS gameplay (not to mention the fact that the campaign and LAN are still playable without servers anyway). However, I contend that Supreme Commander offers a well-crafted, timeless take on the genre that is difficult to replace, so it offers itself as an example, showing that you don’t need to be particularly niche to be sorely missed.
Two points must first be made:
Thankfully, the law could soon protect community-run online game revival efforts in the US, though the Entertainment Software Association opposes this, arguing that laws exempting officially abandoned games from DMCA takedowns can be seen as a form of competition against currently supported titles.
If the legal issues are solved, one might consider that it doesn’t matter too much to get companies to distribute their proprietary game server programs. It’s only a matter of time before someone builds an emulator, and “the problem of building a server emulator is someone else’s problem, not mine”. But what if we avoided the need to emulate from scratch anyway? Instead of thousands of developer hours merely getting something to work, all that effort could instead be fast-tracked with the release of source code or even merely the compiled server programs. Developer hours could instead be spent on improving on what already exists, or even working on completely new projects.
I won’t attempt to discuss the legal aspects of the problem of the release of proprietary game server code (I’m completely the wrong person to talk law), but assuming the legal problems are all sorted, we’d need companies to take an interest in consumer rights, and the technical challenges would need to be addressed. Unfortunately, these require businesses to act on good will, actively costing them man-hours that they technically don’t need to spend.
At the end of the day, the preservation of online videogames is not the end of the world. But the code exists, so why can’t we use it to play these damn videogames?
Recently, Jagex announced the upcoming closure of their mini-games site, Funorb (see the announcement here). Funorb is a childhood favourite of mine, and I absolutely love Arcanists and Steel Sentinels, so it pains me to know that I may never be able to play these games again.
Thankfully, we’ve at least been given 3 months notice along with free paid membership, so I decided to take the opportunity to not only play the game, but record it and dump the videos on YouTube unedited along with full voice chat with my friend.
My original reason was of course for archival purposes. I wanted to record practically all matches I play, perhaps along with commentary, and upload everything mostly unedited. Eventually, I should end up with a big catalogue of videos that I can look through one day to maybe relive the game a bit, from my younger-self’s perspective. I’m making these videos mainly for myself, but I also want to put it out there on YouTube to maybe be discovered by others. If I end up with an audience, then cool, I guess.
Naturally, this prompted another idea:
What if I record all my other gameplay and put it on YouTube?
(Or well, maybe not all my gameplay, but the idea’s there.)
As already discussed, it could be interesting to archive everything, essentially building up a big time capsule of my gameplay. Technically speaking, this entire venture shouldn’t cost me much (although my PC is 6 years old at this point, so it might struggle to record later games). All it should cost is a bit of extra time to set up recording software, then to upload videos to YouTube and enter in metadata.
Future me will thank past me for giving future me all this nostalgia material, and I could use these recordings to:
Putting it on YouTube will also mean it won’t cost me any local storage space - everything is offloaded over to Google’s data centres. However, this does mean losing video quality due to the server-side transcoding. As advances in data storage technology causes significant drops in price and efficiency, I want to eventually keep the lossless recordings, but for the older recordings on YouTube, downloading a lossy compressed copy off YouTube is the best I can do (unless Google miraculously provides original-quality lossless copies in the future.
Although I can put the videos on YouTube publicly, it doesn’t have to be public; I can keep them private, or unlist them for privacy. However, making them public can be great for sharing my experiences, for anyone who cares to watch.
However, that assumes anyone even cares to look. It’s certainly not out of the question that an entire massive archive of raw gameplay footage may never get any views for however long Google decides my videos can be kept for (centuries?). But even if no one watches my videos, I lost nothing.
Unfortunately, putting all this gameplay footage online may be information that could be used against me one day.
Picture this: perhaps one day, I might promise someone to do a certain task at home, but if I don’t get it done (or maybe even if I do), me dumping large amounts of gameplay onto YouTube could be used against me, with accusations along the lines of “if he wasn’t so lazy, this could’ve been completed”, or “if he wasn’t so lazy, this could’ve been done better”.
Someone could also use my video uploading patterns for malicious purposes, such as for planning break-ins.
All of these concerns are also shared with actual professional streamers (such as on Twitch) and professional YouTubers, so I could borrow some of their wisdom.
For instance, I’ll need to ensure that I allow no personal information to leak into my videos. This can be easy if I’m gaming on my own, but it can be more of a problem when I’m casually playing with friends with voice chat. We don’t necessarily always talk about our personal lives, but occasionally, we can get things like:
I’ll also need watch my uploading schedule. Highly frequent video postings can indicate that I’m having a long break from work or school, while gaps in my upload schedule can indicate when I’m heading out for work/school, or if I’m on a long trip overseas (or even domestic). All of these things could be leveraged by someone with the wrong intentions.
Without a recording going on, I’m naturally more relaxed, knowing that everything that’s happening is kept to myself, and I can go as crazy as I want. No one will know.
While recording, I find that there’s added pressure to maintain privacy while also being presentable to the outside world. This can cause undesirable behavioural pattern shifts, such as increased stiffness and acting nervous as though one is in front of an audience, or otherwise simply not acting “natural”. This may also reduce the enjoyment of a videogame.
Sure, I’m not necessarily making these videos for others, but I don’t want to produce something that may be looked on in disgust one day, even if the video is private and the only person who will know is myself.
And even if I’m not the problem, it can be a problem for other people if they’re in the game with me (especially if voice chat is on). Even if people never say that they mind, I’ll still be worried.
I’ve gotten a bit negative with those last two discussion points, so I’d like to discuss a more positive one: satisfaction of producing content with my time.
This is a lot of why I’m maintaining a blog. Content creation is satisfying because I want to produce things for others. Ideas and experiences are great, but sharing them is even better. So why not extend it to gaming? Gaming is already satisfying for the moment-to-moment experiences, so why not try to capture it?
I personally feel that knowing my experiences are captured by screen recording and being intentionally (by myself) saved somewhere is satisfying. My time feels much more well-spent if I produce things, no matter how mundane (such as raw gameplay videos), and I feel more productive while playing videogames this way.
And who knows, maybe I might actually end up building an audience and pivot into producing “proper” gaming content? I’m not exactly sure how that might happen, but then again, I’m not sure many of today’s successful YouTubers in the gaming category knew either. That could be an even funner yet productive way of spending my leisure time while also making a bit of extra money on the side.
It’s an attractive idea, yet also surprisingly complicated. For me, I think I’ll continue exploring this idea of uploading gameplay, although I’ll probably end up uploading the majority of them as private YouTube videos.
For distributed systems class recently, we had to write a simulated distributed network in Erlang.
The assignment involved getting a whole bunch of Erlang processes (which are basically really lightweight threads) to send messages to each other according to the specification. It had a bit of a convoluted way of doing things, but it was intentionally to produce a model that demonstrated an important concept in distributed systems, albeit without the additional complexity layers of socket programming and networking.
I ended up with a bug that wasted an embarrassing number of hours, which got me slowly stepping through a very substantial portion of my program’s functionality in reverse. The entire program culminated into one process producing a small amount of outputs. Being a simulation of a distributed system of several concurrently running nodes, this meant tracing through a web of message-passing.
A lot of the time wasted during debugging was actually due to poor assumptions I made about how the system worked. That’s an entirely separate epic fail on its own (see the appendix section), but that’s not the focus of this particular post.
It turned out that towards the beginning of the entire message exchange, I made a one-character typo. This would’ve been caught instantly with good programming practices.
I’m kinda a super-noob at Erlang and functional programming in general. I literally crash-coursed it over the course of an hour. If I’ve completely missed the mark on something, feel free to yell at me at [email protected].
The erroneous Erlang code took the following form:
if
Foo =:= commited ->
doSomething();
true ->
doSomethingElse()
end,
This is basically equivalent to the following pseudocode if-else:
IF (Foo == commited) THEN
doSomething()
ELSE
doSomethingElse()
END IF
The Foo variable was only expected one of two possible atom values: committed or abort. Because of the typo, doSomethingElse() was always executed, even if doSomething() was meant to be executed instead.
If you’re not familiar with Erlang’s atom type, you can just think of them as a big global enum, and atoms are used in place of things like boolean types, magic number constants, and enum types as seen in other languages. For example, instead of the boolean type, we use the atoms true and false.
From the programmer’s perspective, atom literals can look somewhat like string literals. This makes them particularly susceptible to typos that only get tested during runtime.
Though, using error-prone language constructs doesn’t have to be this painful. All those hours wasted debugging could’ve been solved using one simple technique: writing fast-failing code.
What I should’ve done in my assignment is the following:
case Foo of
commited ->
doSomething();
abort ->
doSomethingElse()
end,
Here, the variable Foo is pattern-matched against the atoms commited and abort. If the case statement fails to find a match, it raises an exception:
Eshell V9.3 (abort with ^G)
1> Foo = committed.
committed
2> case Foo of
2> commited ->
2> doSomething();
2> abort ->
2> doSomethingElse()
2> end.
** exception error: no case clause matching committed
With this version of the code, the error immediately makes itself known, and I would’ve fixed the typo and moved on with my life.
Different languages work differently, so let’s have a look at a similar example in Python. Suppose we had a string that is expected to only be either "committed" or "abort". A fast-failing solution is the following:
if foo == "commited":
do_something()
else:
assert foo == "abort"
do_something_else()
Here, the assert checks that if the else block is entered, foo indeed does have the correct value. This would’ve caught the typo in much the same way as our Erlang solution:
>>> foo = "committed"
>>> if foo == "commited":
... do_something()
... else:
... assert foo == "abort"
... do_something_else()
...
Traceback (most recent call last):
File "<stdin>", line 4, in <module>
AssertionError
However, assert will not work with the -O flag, so if you absolutely have to raise an exception in production, it should be checked in an elif block and an exception raised in the else block:
if foo == "commited":
do_something()
elif foo == "abort":
do_something_else()
else:
raise ValueError("Unexpected value for foo.")
If you haven’t been using fast-failing code before, I hope I’ve convinced you to start using them now. However, fast-fail goes so much deeper than the scope of this post.
For example, asserts are highly versatile in verifying the state of your program at specific points in the code while also usefully doubling as implicit documentation. The following example shows asserts being used to check function preconditions:
def frobnicate(x, y):
assert x < 10
assert isinstance(y, str) and ("frob" in "y")
...
Though, fast-fail is desirable in production, and asserts are usually not checked in production. There are many different practices for raising and handling errors, especially for critical applications such as aeronautics and distributed infrastructure. After all, you wouldn’t want your million-dollar aircraft exploding shortly after launch due to a missing semicolon, or your entire network of servers failing just because one server threw an error.
And of course, I haven’t even touched the ultimate in fast-fail: compile-time errors (as opposed to runtime errors), and statically typed languages (as opposed to dynamically typed languages).
You can certainly still use the Erlang if-statement like so while still failing fast:
Eshell V9.3 (abort with ^G)
1> Foo = committed.
committed
2> if
2> Foo =:= commited ->
2> doSomething();
2> Foo =:= abort ->
2> doSomethingElse()
2> end.
** exception error: no true branch found when evaluating an if expression
However, I personally wouldn’t recommend it for this particular use-case (or even the majority of use-cases) since the case statement here is much clearer, concise, and less error-prone to write.
It should of course also be noted that this is a quirk specific to Erlang. Python would just skip right over the if-statement:
>>> def f(x):
... if x == "commited":
... print("bar")
... elif x == "aborted":
... print("baz")
... print("foo")
...
>>> f("commited")
bar
foo
>>> f("committed")
foo
Be sure to learn the behaviour of your particular language when trying to write fail-fast code.
Also, Python unfortunately lacks such a cases statement, though techniques such as the use of a dictionary may be used if it makes things clearer. The Python dictionary also usefully throws an error if no such key exists:
>>> def f(x):
... {
... "commited": lambda : print("bar"),
... "abort": lambda : print("baz")
... }[x]()
... print("foo")
...
>>> f("commited")
bar
foo
>>> f("committed")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 5, in f
KeyError: 'committed'
I did mention that the way I went about debugging my assignment was its own epic fail, but it’s not particularly deserving of its own separate post so I’ll summarise it here in case it’s of interest to anyone. As a warning though, this explanation might be a bit abstract, and I really don’t blame you if you don’t get it. I’m writing this here for completeness.
Each node in my simulated network potentially spawns a bunch of processes (which I will call “mini processes” for convenience) which it kills only if the network decides to return “abort”. If the network decides to return “committed” instead, the network doesn’t touch them.
These mini processes in my test case receive messages from a controller process after the network makes its committed/abort response.
However, I was finding that despite the network returning “committed”, the messages from the controller process didn’t seem to reach the mini-processes. Or perhaps more accurately, when I put print-statements in the mini-processes, expecting them to all print messages to the terminal, nothing was printed.
Not knowing any better at the time, I focused intensely on why messages sent from one process may not reach a target process.
It took me far too long to realize that the bug as detailed in this blog post caused all nodes to instantly kill all mini-processes since the “abort” code was always executed. The mini-processes were always killed before they could receive the controller’s messages.
Always challenge assumptions, kids.
Lately, I’ve been starting to get back into writing content for this blog, and with that, my perspective on blogging has changed slightly. I’d like to discuss that briefly in this post.
I created this blog to share my views and ideas on various things, all in one place. However, I previously felt like I wanted to achieve some minimum level of “quality”. I wanted this to be a place where if someone were to subscribe, I can give my personal guarantee that they will be reading top-quality, highly-relevant and super-interesting content each and every time I release a new post.
However, wanting to have a high bar of quality I find gets in the way of getting any amount of content out. I’m finding that it leads to chronic procrastination with starting posts, and not to mention the amount of time I spend on any single post, focusing far too much on writing and editing.
And even despite my best efforts to achieve my ideal, I still believe my blog is far from achieving it. Ultimately, all that procrastination and extra writing/editing time has only been wasted. My posts are terribly rambly, my grammar and organization of ideas are lacking greatly, I can get hand-wavy, etc.
So even if I wanted to produce “quality”, I honestly don’t really know how to achieve that right now. I’m not a writer by trade, and I even practically failed highschool English. My grammar will need a huge amount of work, and since I don’t write much, I don’t really have a lot of experience structuring my thoughts and my communication. Sure, I’ve always read a tonne of articles on the internet, but I never really cared about learning how other people structure their writing until now; I just cared that I absorbed the ideas.
As such, I’ve resolved to divorce my previous idea of “quality”. Rather than achieving that elusive “perfect”, “good enough for me” will be my goal. Of course, that’s never a valid excuse to never try to achieve some level of quality, but my focus will instead be on writing for the fun of it, writing what I want to write, and getting ideas out.
Quality should hopefully come naturally over time as I continue this blog.
As I write, I’m constantly reassessing my grammar. If I’m unsure of something, I Google it. In fact, just a minute ago, I Googled et cetera and how the abbreviation etc. is used in writing. I’ve Googled grammar a lot with all my posts, and I hope that continuing to write and learning about grammar and writing this way will naturally lead to an accumulation of knowledge and improvement.
My skill and instinct as a writer should hopefully also continue to improve as I get content out. By getting into the habit of writing, I want to practice identifying cool ideas I want to share with the world, developing habits that help me seek and retain key ideas, developing a better sense of how to structure my ideas in writing, and generally writing faster (rather than taking my time to agonize over how to write).
Structuring my thoughts and building mental habits is also a skill that I want to improve in general. Being kinda a shut-in of a person at the moment, I hate to admit it but my communication skills in general just absolutely suck. Writing should help offset my problem, helping me to eventually integrate into becoming a productive member of society.
For now and hopefully continuing far into the future, I hope to keep using this blog as a “me-blog”. I write because I’m fed up of keeping my thoughts and ideas quietly to myself, and I just want to get them out in some fashion. Thoughts, ideas, and experiences are incredibly valuable yet ephemeral, so I want to capture them in the moment. Not putting them down on record is a damn waste of potential. Someone could’ve been inspired by them!
Now, continually producing content in the way I described is cool and all, but I still want to produce resources one day that meet the “ideal perfect” that I described earlier. My plan is to maybe one day restructure my current blog to sectionalize it, or create new blogs which I might purposefully use for heavy-hitters, or more specific topics. But that’s something for another time.
To hopefully get my content a bit more visibility, I’ll be looking into using Twitter and Reddit to link back to and promote my blog.
I’m a bit of a nooblet when it comes to Twitter though, so let’s see how well this goes…
In my second year of university, I took a class that involved a series of AVR assembly language programming labs. One of them required an implementation of a queue data structure. It was meant to be a simple lab, but an early design decision made it needlessly complicated. This additional complexity single-handedly turned debugging into a nightmare.
My implementation required that all elements be butted up to the front of the buffer. One pointer points to the back.
+---+---+---+---+---+---+
| A | B | C | | | |
+---+---+---+---+---+---+
^
Back
Enqueueing items would add to the back of the queue, and the Back pointer is updated in the process:
+---+---+---+---+---+---+
| A | B | C | D | | |
+---+---+---+---+---+---+
^
Back
Dequeuing would require us to take from the front and shift the remaining elements forward to fill in the space:
+---+---+---+---+---+---+
| B | C | D | | | |
+---+---+---+---+---+---+
^
Back
Hopefully it should be obvious that this makes dequeuing so expensive to accomplish (O(n)) since you’d have to read and write across all the remaining elements in order to do the shifting.
This mistake of choosing the wrong queue implementation bloated the code up by requiring an unnecessarily complex dequeue function to be implemented, and since the function didn’t work the first time around, it took at a nightmarish night of debugging.
The program was failing in such weird ways, and there were so many other possible points of failure, with so many subsystems concurrently running and accessing data all at once. Remember, this is assembly language we’re talking about! If the dequeue function were simpler, I could’ve quickly “proved” that it works as expected, thus allowing me to focus on other places.
In the end, the dequeue function was the problem.
When I proudly presented the final working program to the lab demonstrator, while he was impressed that I got such a thing to work, he was shocked that I even attempted to implement such a thing in the first place. “You realize you could’ve implemented this with a circular buffer, right?”
In a circular buffer, your queue contents are continguously contained somewhere within the queue, not necessarily at the front or back. Two pointers point to the beginning and end.
Front
v
+---+---+---+---+---+---+
| | | A | B | C | |
+---+---+---+---+---+---+
^
Back
Dequeuing would simply grab whatever’s at the front and update the pointer:
Front
v
+---+---+---+---+---+---+
| | | | B | C | |
+---+---+---+---+---+---+
^
Back
And enqueing would simply add to the back and update the pointer:
Front
v
+---+---+---+---+---+---+
| | | | B | C | D |
+---+---+---+---+---+---+
^
Back
If the end of the buffer is reached, we simply wrap to the end, using modular arithmetic to start reading from the beginning again:
Front
v
+---+---+---+---+---+---+
| E | | | B | C | D |
+---+---+---+---+---+---+
^
Back
Simple and fast!
The really obvious takeaway here is to make sure you evaluate your data structures and implementations properly, otherwise you end up giving yourself so much pain later on.
But for me personally, I think at the time, I was a bit too dangerously relaxed about the whole topic of data structures. At that point, I never experienced just how much worse poor design decisions can make everything.
To me, this was a painful yet valuable lesson in ensuring the suitability of a design, and it highlights the importance of mastering and internalizing understanding of data structures and algorithms.