RSS: Syncing Inoreader and Newsboat via. GitHub
Web-based RSS readers are convenient for being a complete online service, but local RSS readers can offer their own advantages. So if you’re looking to get the best of both worlds, here’s my solution.
I use Inoreader as my cloud-based RSS reader, and Newsboat as my local RSS reader.
In summary, the whole thing works using three things:
- Inoreader’s OPML subscription feature,
- Newsboat’s OPML export feature (which I periodically run), and
- Github to host OPML files.
However, this scheme has a problem: I can’t structure my subscriptions! Newsboat only exports a single OPML file, and OPML doesn’t support tags (or similar constructs), so all that structure is lost when Inoreader reads the OPML file.
To solve that problem, I also wrote a script to separate the original OPML file into separate OPML files (one for each tag).
So how does everything work?
(Note: I assume basic familiarity with Inoreader, Newsboat, Git, GitHub, and automation/scripting.)
The OPML file format
OPML is a file format that contains a list of web feeds. These are often used to export/import RSS subscriptions between different RSS readers.
For example, if you’re using Feedly and you one day decide you want to switch to Inoreader, you can download all of your subscriptions from Feedly to your computer as an OPML file, then upload that file to Inoreader. Inoreader now has all your Feedly subscriptions.
Here’s an example OPML file:
<?xml version="1.0"?>
<opml version="1.0">
<head>
<title>newsboat - Exported Feeds</title>
</head>
<body>
<outline type="rss" xmlUrl="http://simshadows.com/feed.xml" htmlUrl="http://simshadows.com//" title="Sim's Blog"/>
<outline type="rss" xmlUrl="http://kuvshinov-ilya.tumblr.com/rss" htmlUrl="http://kuvshinov-ilya.tumblr.com/" title="Kuvshinov Ilya"/>
<outline type="rss" xmlUrl="https://xkcd.com/rss.xml" htmlUrl="https://xkcd.com/" title="xkcd"/>
<outline type="rss" xmlUrl="https://googleprojectzero.blogspot.com/feeds/posts/default" htmlUrl="https://googleprojectzero.blogspot.com/" title="Google Project Zero"/>
</body>
</opml>
Newsboat’s subscriptions storage and OPML export
Normally, your Newsboat subscriptions are stored in the ~/.newsboat/urls file. Mine can be found here.
To export everything into an OPML file, run the following command:
newsboat -e > ~/subs.xml
My exported OPML file can be found at https://github.com/simshadows/sims-dotfiles/blob/master/dotfiles/newsboat/autogenerated-opml/ORIGINAL.xml.
Inoreader’s OPML subscription feature
When you add an OPML subscription to Inoreader, it periodically pings a URL containing an OPML file to monitor it for changes, which keeps your Inoreader subscriptions synchronized with it. This is literally the same basic principle in which RSS works!
Here are my OPML subscriptions at the time of writing:
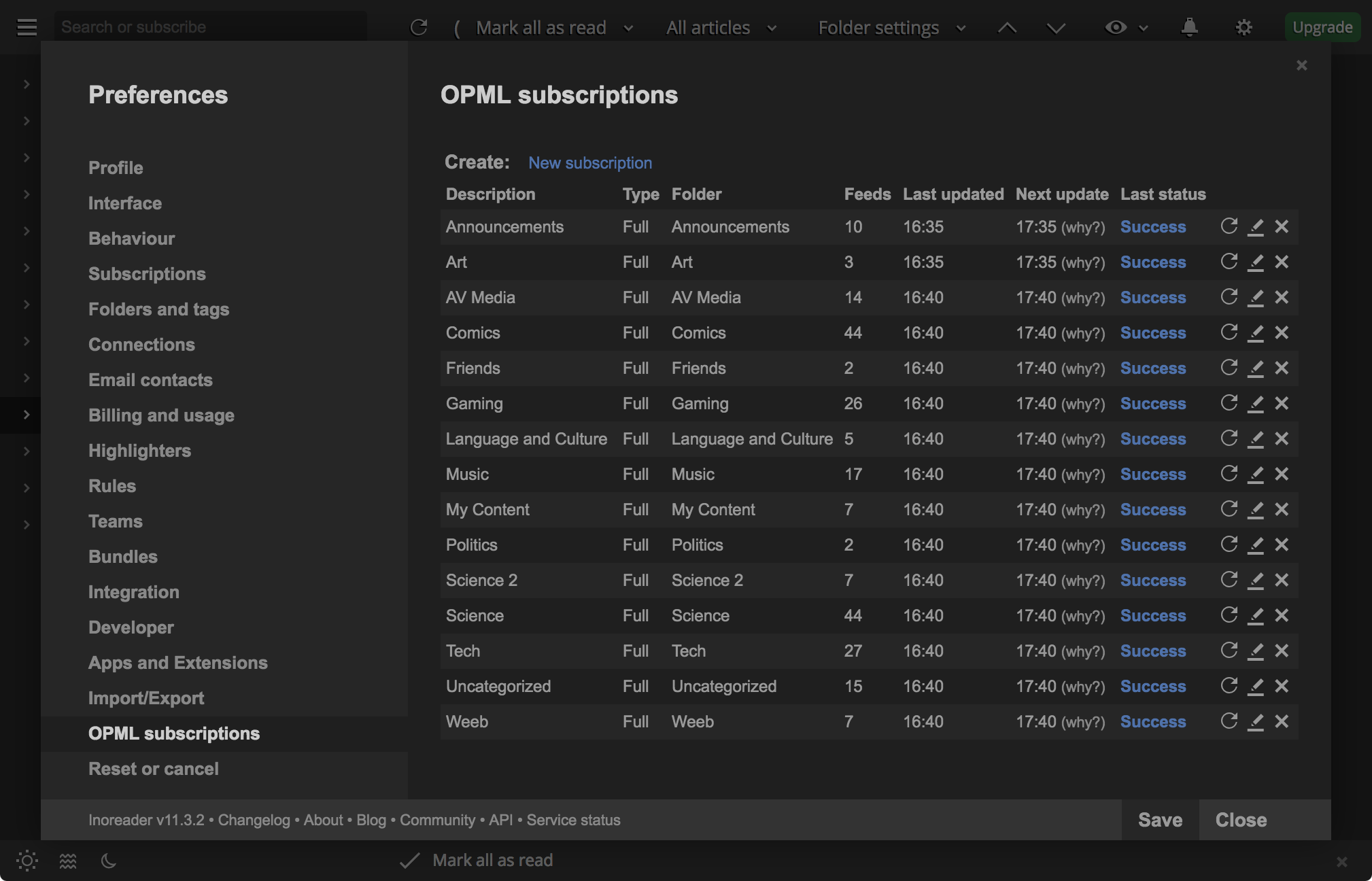
Each OPML subscription in Inoreader is associated with a particular tag.
Hosting the OPML file on Github
In order to use Inoreader’s OPML subscription on our Newsboat OPML export, we need a way to host the OPML file on the internet. This is where GitHub comes in.
With Github, just git push your file up to your public repository, and grab the URL to the *RAW* file and subscribe to it with Inoreader. Every time you update, git push again and Inoreader automatically updates your Inoreader subscriptions!
You can find my raw OPML file at: https://raw.githubusercontent.com/simshadows/sims-dotfiles/master/dotfiles/newsboat/autogenerated-opml/ORIGINAL.xml
Splitting up the OPML file by tag
As I mentioned before, you lose the tag structure from the ~/.newsboat/.urls file if you just use the raw OPML export from Newsboat, and I solved the problem with a script that separates the original OPML file into separate OPML files (one for each tag).
All the script does is:
- Parse the
~/newsboat/.urlsfile for tags. - For each tag, make an exact copy of the original OPML file, except remove the lines containing subscriptions that don’t belong in the file.
For example, if we start with the following ~/.newsboat/urls file:
https://www.nasa.gov/rss/dyn/breaking_news.rss "Science"
http://www.folk-metal.nl/feed/ "Music"
https://myanimelist.net/rss/news.xml "Weeb"
And we the following OPML file:
<?xml version="1.0"?>
<opml version="1.0">
<head>
<title>newsboat - Exported Feeds</title>
</head>
<body>
<outline type="rss" xmlUrl="https://www.nasa.gov/rss/dyn/breaking_news.rss" htmlUrl="http://www.nasa.gov/" title="NASA Breaking News"/></body>
<outline type="rss" xmlUrl="http://www.folk-metal.nl/feed/" htmlUrl="http://www.folk-metal.nl" title="Folk-metal.nl"/>
<outline type="rss" xmlUrl="https://myanimelist.net/rss/news.xml" htmlUrl="https://myanimelist.net/news?_location=rss" title="News - MyAnimeList"/>
</opml>
To generate an OPML file for the Music tag, we simply copy over the original OPML file while deleting all unrelated entries, like so:
<?xml version="1.0"?>
<opml version="1.0">
<head>
<title>newsboat - Exported Feeds</title>
</head>
<body>
<outline type="rss" xmlUrl="http://www.folk-metal.nl/feed/" htmlUrl="http://www.folk-metal.nl" title="Folk-metal.nl"/>
</opml>
It’s really that simple! Just subscribe to each separate OPML file on Inoreader.
My implementation is technically actually split between two scripts:
- https://github.com/simshadows/sims-dotfiles/blob/master/dotfiles/newsboat/autogen.sh
- https://github.com/simshadows/sims-dotfiles/blob/master/dotfiles/newsboat/split-opml-by-tags.py
However, I wrote these scripts to fit my repository’s style (and the code’s not very robust), so I suggest you write your own.
You can also find my OPML files for each tag here: https://github.com/simshadows/sims-dotfiles/tree/master/dotfiles/newsboat/autogenerated-opml